angel
Support Vector Machine(SVM)
SVM支持向量机器是一种常用的分类算法
1. 算法介绍
SVM分类模型可以抽象为以下优化问题:
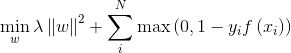
其中:
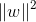 为正则项;
为正则项;
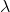 为正则项系数;
为正则项系数;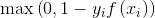 为合页损失函数(hinge loss),如下图所示:
为合页损失函数(hinge loss),如下图所示:
2. 分布式实现 on Angel
Angel MLLib提供了用mini-batch gradient descent优化方法求解的SVM二分类算法,算法逻辑如下:

3. 运行 & 性能
输入格式
数据的格式通过“ml.data.type”参数设置;数据特征的个数,即特征向量的维度通过参数“ml.feature.num”设置。 LR on Angel支持“libsvm”、“dummy”两种数据格式,分别如下所示:
- dummy格式: 每行文本表示一个样本,每个样本的格式为”y index1 index2 index3 …“。其中:index特征的ID;训练数据的y为样本的类别,可以取1、-1两个值;预测数据的y为样本的ID值。比如,属于正类的样本[2.0, 3.1, 0.0, 0.0, -1, 2.2]的文本表示为“1 0 1 4 5”,其中“1”为类别,“0 1 4 5”表示特征向量的第0、1、4、5个维度的值不为0。同理,属于负类的样本[2.0, 0.0, 0.1, 0.0, 0.0, 0.0]被表示为“-1 0 2”。
- libsvm格式: 每行文本表示一个样本,每个样本的格式为”y index1:value1 index2:value1 index3:value3 …“。其中:index为特征的ID,value为对应的特征值;训练数据的y为样本的类别,可以取1、-1两个值;预测数据的y为样本的ID值。比如,属于正类的样本[2.0, 3.1, 0.0, 0.0, -1, 2.2]的文本表示为“1 0:2.0 1:3.1 4:-1 5:2.2”,其中“1”为类别,”0:2.0”表示第0个特征的值为2.0。同理,属于负类的样本[2.0, 0.0, 0.1, 0.0, 0.0, 0.0]被表示为“-1 0:2.0 2:0.1”。
参数
- 算法参数
- ml.epochnum:迭代次数
- ml.batch.sample.ratio:每次迭代的样本采样率
- ml.sgd.batch.num:每次迭代的mini-batch的个数
- ml.validate.ratio:每次validation的样本比率,设为0时不做validation
- ml.learn.rate:初始学习速率
- ml.learn.decay:学习速率衰减系数
- ml.reg.l2:L2惩罚项系数
- 输入输出参数
- angel.train.data.path:训练数据的输入路径
- angel.predict.data.path:预测数据的输入路径
- ml.feature.num:数据特征个数
- ml.data.type:数据格式,支持”dummy”、”libsvm”
- angel.save.model.path:训练完成后,模型的保存路径
- angel.predict.out.path:预测结果存储路径
- angel.log.path:log文件保存路径
- 资源参数
- angel.workergroup.number:Worker个数
- angel.worker.memory.mb:Worker申请内存大小
- angel.worker.task.number:每个Worker上的task的个数,默认为1
- angel.ps.number:PS个数
- angel.ps.memory.mb:PS申请内存大小!
- 其它参数配置
- 模型输出路径删除: 为了防止误删除模型,Angel默认不自动删除模型输出路径的文件。如果需要删除,要在Angel参数框内填入angel.output.path.deleteonexist=true