angel
模型分区(Model Partitioner)
为了支持超大模型,无论是宽模型还是深模型,Angel都需要将模型切分为多个部分,存储在不同的PSServer节点上,并提供方便的访问服务,这是参数服务器的本质,也是最基本的功能之一。
模型的划分方式是一个参数服务器设计中,非常值得关注的通用性工程问题,不同的划分方式可能导致计算性能上的差异。一个好的模型划分,应该考虑如下的方面:
- 保证PS负载均衡
- 降低PS单点性能瓶颈
- 关联的数据在同一个PS上
但是在实际应用中,各个算法,或者一个算法的各种实现,对划分方式要求都不一样。因此,Angel既提供了默认划分算法用来满足一般的划分需求,也提供了自定义划分的功能,来满足特殊的需求。
整体设计
Angel的模型分区,整体设计如下:

需要注意的是:
- 对于用户来说,入口类是PSModel,尽量通过它操作
- 默认的分区类为PSPartitioner,但是它可以被替换
- 分区(Partition)是最小的单位,每个分区对应着PSServer上具体的Model Shard
PSServer会在Load Model阶段,根据传入的Partitioner进行Model Shard的初始化。因此Model Partitioner的设计,和运行时的真实模型数据,会影响PS Server上的模型分布和行为。
默认的模型分区(PSPartitioner)
在Angel中,模型使用Martrix来表示。当应用程序没有指定Martrix划分参数或者方法时,Angel将使用默认的划分算法。默认的划分算法遵循以下几个原则:
- 尽量将一个模型平均分配到所有PS节点上
- 对于非常小的模型,将它们尽量放在一个PS节点上
- 对于多行的模型,尽量将同一行放在一个PS节点上
分区(Partition)大小
由于Angel底层的部分RPC接口,是以矩阵分区为单位来操作的,为了避免消息过大,Angel设置了一个最大消息限制100MB(可通过参数angel.netty.matrixtransfer.max.message.size 配置)所以一般矩阵分区占用存储空间不要超过这个限制值。
所以,Angel一般推荐的单个分区大小为10MB-40MB,以分区大小40MB为例,大概可以容纳40 * 10^6 / 8 = 5,000,000个Double型元素。因此,默认的分区算法,以5,000,000这个值为默认阈值。
默认分区算法
假定row为整个矩阵的行数,col为整个矩阵的列数,serverNum为PS个数。
- 当矩阵行数大于等于PS个数
# 分区块行数
blockRow = Math.min(row / serverNum, Math.max(1, 5000000 / col))
# 分区块列数
blockCol = Math.min(5000000 / blockRow, col)
- 当矩阵行数小于PS个数时
# 分区块行数
blockRow = row
# 分区块列数
blockCol = Math.min(5000000 / blockRow, Math.max(100, col / serverNum))`
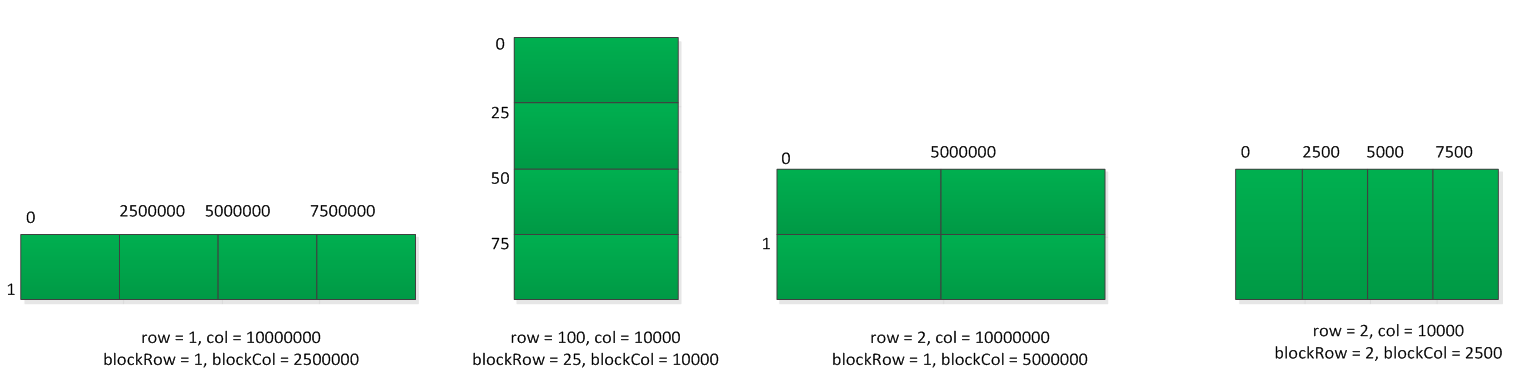
按照默认的分区算法,假设serverNum = 4,下图是几个典型的模型,它们的矩阵分区情况:
自定义的模型分区
为了实现更加复杂的模型分区方式,适用于复杂的算法。Angel允许用户自定义矩阵分区的大小,并且有两种方法。
-
简单方法:在定义PSModel时,传入blockRow和blockCol
val sketch = PSModel[TDoubleVector](modelName, sampleNum, featNum, blockRow, blockCol)通过这种方式,用户可以轻松控制矩阵分区的大小,满足需求,但仍然不够灵活。
-
高阶方法:设置自定义的Partitioner
当算法非常复杂时,会有奇奇怪怪的需求,例如:
- 有时候矩阵各个部分访问频率并不一样时
- 不同的分区有不同的大小
- 将某些存在关联的分区放到同一个PS上
- ……
为了满足这些特殊算法和模型的需求,Angel抽象了一个分区接口Partitioner,PSPartitioner只是其中一个默认实现,用户可以通过实现Partitioner接口来实现自定义的模型分区方式,并注入到PSModel之中,轻松改变模型的分区行为。
Partitioner接口的定义如下:
interface Partitioner { /** * Init matrix partitioner * @param mContext matrix context * @param conf */ void init(MatrixContext mContext, Configuration conf); /** * Generate the partitions for the matrix * @return the partitions for the matrix */ List<MLProtos.Partition> getPartitions(); /** * Assign a matrix partition to a parameter server * @param partId matrix partition id * @return parameter server index */ int assignPartToServer(int partId); }用户需要实现的接口有两个
getPartitions和assignPartToServergetPartitions表示获取该矩阵的分区列表assignPartToServer表示如何决定一个分区分配给某一个PSServer
下面通过一个简单的例子来说明如何通过实现Partitioner接口来自定义矩阵划分方式。假设有这样的使用场景:
- 模型是一个
3 * 10,000,000维的矩阵,PS个数为8,其中,第一行访问的非常频繁
为此,我们需要如下的分区策略:
- 第一行分区的小一些,划分成4个分区,每一行分布到4个PS之上
- 其他行的划分成2个分区,每一行分布到2个PS之上
如图3所示:

由于分区的大小并不相同,所以默认的分区方式没有办法实现这样的需求,这个时候可以定制一个分区类CustomizedPartitioner:
public class CustomizedPartitioner implements Partitioner { …… @Override public List<MLProtos.Partition> getPartitions() { List<MLProtos.Partition> partitions = new ArrayList<MLProtos.Partition>(6); int row = mContext.getRowNum(); int col = mContext.getColNum(); int blockCol = col / 4; int partitionId = 0; // Split the first row to 4 partitions for (int i = 0; i < 4; i++) { if (i < 3) { partitions.add(MLProtos.Partition.newBuilder().setMatrixId(mContext.getId()) .setPartitionId(partitionId++).setStartRow(0).setEndRow(1).setStartCol(i * blockCol) .setEndCol((i + 1) * blockCol).build()); } else { partitions.add(MLProtos.Partition.newBuilder().setMatrixId(mContext.getId()) .setPartitionId(partitionId++).setStartRow(0).setEndRow(1).setStartCol(i * blockCol) .setEndCol(col).build()); } } blockCol = col / 2; // Split other row to 2 partitions for (int rowIndex = 1; rowIndex < row; rowIndex++) { partitions.add( MLProtos.Partition.newBuilder().setMatrixId(mContext.getId()).setPartitionId(partitionId++) .setStartRow(rowIndex).setEndRow(rowIndex + 1).setStartCol(0).setEndCol(blockCol) .build()); partitions.add( MLProtos.Partition.newBuilder().setMatrixId(mContext.getId()).setPartitionId(partitionId++) .setStartRow(rowIndex).setEndRow(rowIndex + 1).setStartCol(blockCol).setEndCol(col) .build()); } return partitions; } …… }实现了该CustomizedPartitioner后,将其注入到PSModel的MatrixContext之中,就能实现自定义的模型分区了
psModel.matrixCtx.setPartitioner(new CustomizedPartitioner());
通过默认的模型分区策略,和自定义的模型分区策略,Angel的模型分区上,在方便性和灵活性,做出了很好的平衡,为用户实现高效的复杂算法,打下了良好的基础。